Abstract
- Identity and Access Management (IAM) always requires some type of password store or database.
- The majority of IAM cases are handled by simple key-value password stores.
- Even when more powerful and fine-grained relational databases are employed, SQL joins are complex and slow, and the results are often cached in simple key-value stores in memory anyways.
- Graph databases are a novel solution to this problem, providing the elegance of relational databases without the complex and slow SQL joins that make caching necessary.
What is a Database?
In the most abstract sense of the word, a database is simply a collection of data. Databases have two basic functions: to store data and to allow access to that data. A Database Management System, or DBMS is the computer software that allows users to interact with the data, usually via application. The words DBMS and Database are used interchangeably. Databases vary greatly in how they store data and allow access to data, most importantly by changing how that data is organized for storage and retrieval. The main types of data organization are relational databases (RDBMSs) accessed via SQL, which are the most common type, and NoSQL databases, which include key value databases, document databases and graph databases.
Use case:
There is a dizzying array of database types, but the one you choose depends heavily on your use case. For the purpose of illustrating the difference between four different types of databases, I will choose to talk about identity and access management, (IAM). For this example, imagine that we want to password protect a website or web application. Identity is how we guarantee that a user is who they say they are, via a password, a private/public key, a single sign on (SSO) using a trusted account like Google, Facebook or LinkedIn, or using two factor or multifactor authentication like an SMS or email one time password, or rotating security token. Once the user’s identity is verified, access management determines what type of access the user has to various parts of the website or application.
Key Value Databases
A key-value database is a data storage paradigm that is referred to, depending on programming language, as an associative array, a dictionary, or a hash table. A key-value database is one of the major types of NoSQL databases.
Storage:
In a key-value database, data is stored as a collection of objects, alternatively called records or rows. Each record contains a set of fields of information called values, one of which is designated the key. The key must be chosen wisely as it must always be unique. The value fields can contain any type of data and can contain duplicates.
Interface:
When retrieving data from a key-value database, all that is necessary is to provide the key, and the values will be returned. Interfaces vary widely between implementations, but as queries are extremely simplistic, there is little need for standardization.
Examples:
Berkley BD Berkley DB was developed at the University of California, Berkley as part of BSD, Berkey’s version of the Unix operating system, which runs many of the servers of the world and is at the core of today’s Mac OS X and iOS. It has powered many applications like mail servers (sendmail, postfix) source control servers (subversion), memory caches (memcacheD, Voldemort), spam filters (spamassassin and bogofilter), and the initial release of Bitcoin. It is now maintained by Oracle as Oracle NoSQL. Redis Redis is an open-source, distributed, in-memory key-value database, cache and message broker that can store anything from text to binary data and streams. It is the most popular key-value database today. It is widely used for user session caching, page caching, and message queue applications.
Identity and Access Management Example:
Apache is the world’s most popular webserver and powers an extremely large percentage of the world’s most popular websites consistently for the past 25 years. It has a built-in mechanism for password protecting directories on a website: .htpasswd files. Although this is not a standalone key-value database, this is one of the most common ways that sites are password protected, and it is a key-value datastore.
A .htpasswd file is just that, a file. Each line in the file represents a key: the unique username, and a hash of the password. When a user navigates to a website, Apache responds to the broswer’s request by returning the contents of an html file on the filesystem of the server. If Apache is configured to check for an .htpasswd file in order to serve that particular html file, it will prompt the user for a username and password. When the user enters the username and password, apache looks up the username as the key of the key-value pair, and then retrieves the hash of the password. If the username does not exist, or the hashes of the given and stored passwords do not compare, access is denied. If the hash of the two passwords is the same, then apache will return the contents of the protected html file to the user’s browser. Note: The file contains hashes of the password, not the password itself, so if the .htpasswd file is compromised, the user’s passwords are not.
Here are the contents of a sample .htpasswd file:
somebody@gmailcom:RLjXiyxx56D9s admin:RLMzFazUFPVRE JohnW:RL8wKTlBoVLKk
In order to provide an easy way to manage users in an .htpasswd file without worrying about how to create a hash of the password using an encryption library, apache comes with a simple command line tool called htpasswd. To add a user named "randy " with a password of "badpassword123 " to the .htpasswd file, you would type the following on the unix command prompt, referencing the correct .htpasswd file:
htpasswd -db ./.htpasswd randy badpassword123
The .htpassword file would then contain a new record:
somebody@gmailcom:RLjXiyxx56D9s admin:RLMzFazUFPVRE JohnW:RL8wKTlBoVLKk randy:se342AFYDkFVS
To remove access for JohnW. I would simply type
htpasswd -D ./.htpasswd JohnW
The .htpasswd file would then reflect the deletion:
somebody@gmailcom:RLjXiyxx56D9s admin:RLMzFazUFPVRE randy:se342AFYDkFVS
Now when I would attempt to navigate to a part of a website protected by this file, apache would ask me for a username and password. When I enter randy as the username and "badpassword123 " as the password, apache will hash "badpassword123" and come with "se342AFYDkFVS ". It will then look up the value for the key "randy", and because the value for randy is also "se342AFYDkFVS", access is granted and my browser will display the password protected files.
For more information, see apache’s website
Extending key value pair databases
It is important to note that the value is not limited to a single value. It would be easy to imagine a situation where we wanted to store the full name of the user and if they have readonly or write permissions to the resources. We could easily expand a key value database to store this information.
Instead of storing a row as:
randy:se342AFYDkFVS
we could store
randy:Randy Weinstein:write:se342AFYDkFVS
where the first row would still be the key by which we look up the values, but the values for the key "randy" would include "Randy Weinstein", "write", and "se342AFYDkFVS". The important thing about a key value database is that there is a single unique key for each row, not the number of values. The issue here is that if we add more fields to the row, we have little metadata about what each field is. How do we know that the second field "Randy Weinstein" is the user’s full name and not their password?
Enter document databases.
Document Databases
A document database is a type of key value database that keeps metadata about the values that it is storing. Two ways that it might do this are XML and JSON, common formats for displaying data along with associated metadata that describes the data. For example, instead of storing randy:Randy Weinstein:write:se342AFYDkFVS JohnW:John White:read:RL8wKTlBoVLKk In a JSON format, this could be stored as:
{
"username": "randy",
"fullname": "Randy Weinstein",
"permission": "write",
"passwordhash": "se342AFYDkFVS"
},
{
"username": "JohnW",
"fullname": "John White",
"permission": "read",
"passwordhash": "RL8wKTlBoVLKk"
}
In XML, this document might look like this:
<contact>
<username>randy</username>
<fullname>Randy Weinstein</fullname>
<permission>write</permission>
<passwordhash>se342AFYDkFVS</passwordhash>
</contact>
<contact>
<username>JohnW</username>
<fullname>John White</fullname>
<permission>read</permission>
<passwordhash>RL8wKTlBoVLKk</passwordhash>
</contact>
Examples:
MongoDB MongoDB is a popular JSON backed document database. It is open-sourced, but backed by a publicly traded company listed on NASDAQ and offered by Alibaba Cloud as a service. Amazon offers a MongoDB compliant database called DocumentDB, which in fact powers this blog as you are reading it now. MongoDB has grown to include support for advanced querying , indexing, replication, load balancing via sharding, server side Javascript execution for queries and aggregation functions such as MapReduce, and almost fully ACID compliant transactions. Elasticsearch Elasticsearch is the most popular search engine that has powered much of the big data capabilities at my last few gigs, including my current job at Efundamentals. It provides scalable, near real-time search backed by sharded schema-free JSON documents. It is offered as a service by google as Elastic Cloud in GCP and Elasticsearch and Kibana in Alibaba Cloud. AWS also offers Elasticsearch as a managed service since 2015.
Schema on read vs. schema on write
At this moment, every database that we have talked about is considered a NoSQL database, and also Schema on Read. That means that you can store any type of arbitrary data in the database, with or without metadata, and it is up to the application to handle the data format on at read time.
This means that there is no enforcement as to whether there is a full name, a permissions field, or even a password hash, or in what order. The application must handle the unexpected at read time. Enter SQL databases, also known as relational databases. Relational databases define the relationships between data upfront and will not accept the insertion of data that does not meet the requirements of the relational schema. This is called Schema on Write.
Relational Databases
Relational databases store information in tables, conforming to a schema which defines the relationships between the tables. In its simplest form, a relational database has one table. You can create this table using SQL.
create database test1;
use test1;
create table Users ( id int, username varchar(255), passwordhash varchar(255), fullname varchar(255));
insert into Users values(1, "JohnW", "RL8wKTlBoVLKk", "John White");
insert into Users values(2, "randy", "se342AFYDkFVS", "Randy Weinstein");
This gives us the following table:
| id | username | passwordhash | fullname |
|---|---|---|---|
| 1 | JohnW | RL8wKTlBoVLKk | John White |
| 2 | randy | se342AFYDkFVS | Randy Weinstein |
Now we can use SQL to select the password hash from the table based on the username.
select passwordhash from Users where username = 'randy';
se342AFYDkFVS
Idenity is confirmed! But what about access?
Let’s add some more tables and relationships.
use test1;
create table UserRoles ( user int, role int);
create table Roles ( id int, name varchar(255));
insert into Roles values(1, "Admin");
insert into Roles values(2, "Public");
insert into UserRoles values( 1, 2);
insert into UserRoles values( 2, 1);
We now have three tables:
| id | username | passwordhash | fullname |
|---|---|---|---|
| 1 | JohnW | RL8wKTlBoVLKk | John White |
| 2 | randy | se342AFYDkFVS | Randy Weinstein |
| user | role |
|---|---|
| 1 | 2 |
| 2 | 1 |
| id | name |
|---|---|
| 1 | Admin |
| 2 | Public |
Now we can use SQL to look up the role for a given username and password:
select Roles.name
from Users, UserRoles, Roles
where Users.id = UserRoles.user
and Roles.id = UserRoles.role
and Users.username = 'randy' and Users.passwordhash = 'se342AFYDkFVS';
SQL says that randy has the role of "Admin"
How about JohnW?
select Roles.name
from Users, UserRoles, Roles
where Users.id = UserRoles.user
and Roles.id = UserRoles.role
and Users.username = JohnW and Users.passwordhash = RL8wKTlBoVLKk;
SQL says that JohnW has the role of "Guest"
Now let’s add some tables that define actual URLs and some role-based permissions for those URLs:
use test1;
create table Resources ( id int, path varchar(255));
create table RolePermissions ( role int, resource int, permission varchar(255));
insert into Resources values( 1, "/admin");
insert into Resources values (2, "/blog");
insert into RolePermissions values ( 1, 1, "Write");
insert into RolePermissions values ( 2, 1, "None");
insert into RolePermissions values ( 1, 2, "Write");
insert into RolePermissions values ( 2, 2, "Read");
We’ve now just added the following 2 tables to our database, bringing the total tables to 5:
| role | resource | permission |
|---|---|---|
| 1 | 1 | Write |
| 2 | 1 | None |
| 1 | 2 | Write |
| 2 | 2 | Read |
| id | path |
|---|---|
| 1 | /admin |
| 2 | /blog |
Now we can use the following SQL to see what access 'randy' with passwordhash 'se342AFYDkFVS' has on the '/admin' URL
select RolePermissions.permission
from Users, UserRoles, Roles, RolePermissions, Resources
where Users.id = UserRoles.user
and Roles.id = UserRoles.role
and RolePermissions.role = Roles.id
and RolePermissions.resource = Resources.id
and Users.username = 'randy' and Users.passwordhash = 'se342AFYDkFVS'
and Resources.path = '/admin';
SQL returns "Write "
Let’s use the same SQL to see what access 'JohnW' with passwordhash 'RL8wKTlBoVLKk' has on the '/admin' URL
select RolePermissions.permission
from Users, UserRoles, Roles, RolePermissions, Resources
where Users.id = UserRoles.user
and Roles.id = UserRoles.role
and RolePermissions.role = Roles.id
and RolePermissions.resource = Resources.id
and Users.username = 'JohnW' and Users.passwordhash = 'RL8wKTlBoVLKk'
and Resources.path = '/admin';
SQL Returns "None "
In reality, identity has moved well beyond password hashes stored in a database for most modern applications, but once identity is confirmed, this is how most real-world applications control access to various resources today. The elegance of the solution to provide fine grained roles and permissions to groups of users within a tightly controlled database schema provides system administrators considerable power and flexibility. The issue is, however, that as the system grows in complexity, the complexity of the SQL statements joining data in an ever-increasing amount of database tables becomes slow and difficult to maintain, and permissions, once fetched, end up being cached in a simple key value database in memory for performance reasons anyways.
Enter graph databases.
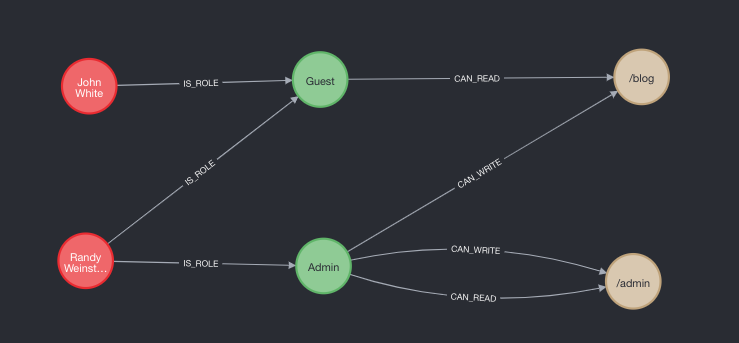
Graph Databases
A graph database is a NoSQL database that elevates the relationships between actors to first class entities. In other words, a User, a Role, a Permission are all first level entitles much as they were in the previous relational example and can have properties like name and password. However, the relationship between these entities are also first level entities and can have properties as well. For example, a Role can have a relationship with a Resource. The role might have a property set to &Admin&, and the Resource might have a property called "path" set to "/admin", but the relationship linking them is no longer a lookup table with a couple columns of meaningless numbers, but a full-fledged entitiy , with it’s own properties like "type", "created_by“, "valid_from", "valid_until".
For example, take the following SQL that we wrote to create the previous relational database example
create database test1;
use test1;
create table Users ( id int, username varchar(255), passwordhash varchar(255), fullname varchar(255));
insert into Users values(1, "JohnW", "RL8wKTlBoVLKk", "John White");
insert into Users values(2, "randy", "se342AFYDkFVS", "Randy Weinstein");
create table UserRoles ( user int, role int);
create table Roles ( id int, name varchar(255));
insert into Roles values(1, "Admin");
insert into Roles values(2, "Public");
insert into UserRoles values( 1, 2);
insert into UserRoles values( 2, 1);
create table Resources ( id int, path varchar(255));
create table RolePermissions ( role int, resource int, permission varchar(255));
insert into Resources values( 1, "/admin");
insert into Resources values (2, "/blog");
insert into RolePermissions values ( 1, 1, "Write");
insert into RolePermissions values ( 2, 1, "None");
insert into RolePermissions values ( 1, 2, "Write");
insert into RolePermissions values ( 2, 2, "Read");
This can be re-writen with the Cypher language instead of SQL and used to create a graph database in Neo4J. Excuse the verbosity of the Cypher code, I am just learning it as I write this. In fact this is the first Cypher code I have ever written.
CREATE (userrandy:User {username:'randy', passwordhash:"se342AFYDkFVS", fullname:"Randy Weinstein" })
CREATE (userjohn:User {username:'JohnW', passwordhash:"RL8wKTlBoVLKk", fullname:"John White" })
CREATE (adminrole:Role {name:'Admin'})
CREATE (guestrole:Role {name:'Guest'})
CREATE (adminresource:Resource {path:'/admin'})
CREATE (blogresource:Resource {path:'/blog'})
CREATE (userrandy)-[rel1:IS_ROLE]->(adminrole)
CREATE (userrandy)-[rel2:IS_ROLE]->(guestrole)
CREATE (userjohn)-[rel3:IS_ROLE]->(guestrole)
CREATE (guestrole)-[rel4:CAN_READ]->(blogresource)
CREATE (adminrole)-[rel5:CAN_WRITE]->(blogresource)
CREATE (adminrole)-[rel6:CAN_WRITE]->(adminresource)
CREATE (adminrole)-[rel7:CAN_READ]->(adminresource)
So at this moment, it doesn’t look like we have gained much compared to a relational database. But wait, check out the visualization feature in Neo4J that shows us what we have created. This is much easier to understand than the previous relational exmaple!

Here is the value. In the previous example, to check if the “randy” user had access to the path “/admin”, this was our SQL
select RolePermissions.permission
from Users, UserRoles, Roles, RolePermissions, Resources
where Users.id = UserRoles.user
and Roles.id = UserRoles.role
and RolePermissions.role = Roles.id
and RolePermissions.resource = Resources.id
and Users.username = 'randy' and Users.passwordhash = 'se342AFYDkFVS'
and Resources.path = '/admin';
In Cypher using Neo4J, here is our equivalent statement:
MATCH (:User {username: "randy", passwordhash: "se342AFYDkFVS"})-[:IS_ROLE]->(:Role)-[rel]->(:Resource {path:'/admin'})
RETURN DISTINCT collect(type(rel)) as Permissions
This query matches the correct User nodes by username and password, follows all the IS_ROLE relationships to find all the roles the user has, and then finds all of the relationships that those roles have with the corresponding Resource node with path “/admin”. The result is a list of all the relationships that a user has for the given resource via all of it’s roles. The result looks like this:
["CAN_READ", "CAN_WRITE"]
Here is a video from Neo4J talking about this use case:
Conclusion:
Between simple key-value use cases and relational databases, we have 99 % of the real-world implementations of this use case covered. I purposely left graph databases for last because it is probably less than 1 % of the world that uses them in this fashion. But graph databases are a newer technology and I expect that 1 % to rise steadily over the years. Cypher code is significantly easier to write and maintain than SQL and is less prone to errors. Errors are bad when dealing with Identity and Access Management, so if you are considering using a graph database for this use case, I give your choice two thumbs up!